import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)2.18.0import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)2.18.0# import requests
# url = "https://cdn.freecodecamp.org/project-data/sms/train-data.tsv"
# query_parameters = {"downloadformat": "tsv"}
# response = requests.get(url, params=query_parameters)
# with open("train-data.tsv", mode="wb") as file:
# file.write(response.content)
# url = "https://cdn.freecodecamp.org/project-data/sms/valid-data.tsv"
# query_parameters = {"downloadformat": "tsv"}
# response = requests.get(url, params=query_parameters)
# with open("valid-data.tsv", mode="wb") as file:
# file.write(response.content)train_file_path = "train-data.tsv"
test_file_path = "valid-data.tsv"header_names = ["label", "message"]
df_train = pd.read_csv(
train_file_path, sep="\t", encoding="utf-8", header=None, names=header_names
)
df_test = pd.read_csv(
test_file_path, sep="\t", encoding="utf-8", header=None, names=header_names
)df_test.sample(5)| label | message | |
|---|---|---|
| 1349 | ham | yeah sure thing mate haunt got all my stuff so... |
| 725 | ham | i just got home babe, are you still awake ? |
| 234 | ham | finally it has happened..! aftr decades..! bee... |
| 1191 | ham | it‘s £6 to get in, is that ok? |
| 715 | ham | hello. damn this christmas thing. i think i ha... |
label_map = {"ham": 0, "spam": 1}
df_train["label"] = df_train["label"].map(label_map)
df_test["label"] = df_test["label"].map(label_map)entity_map = {
"!": "!",
""": '"',
"#": "#",
"$": "$",
"%": "%",
"&": "&",
"'": "'",
"(": "(",
")": ")",
"*": "*",
"+": "+",
",": ",",
"-": "-",
".": ".",
"/": "/",
"0": "0",
"1": "1",
"2": "2",
"3": "3",
"4": "4",
"5": "5",
"6": "6",
"7": "7",
"8": "8",
"9": "9",
":": ":",
";": ";",
"<": "<",
"=": "=",
">": ">",
"?": "?",
"@": "@",
"A": "A",
"B": "B",
"C": "C",
"D": "D",
"E": "E",
"F": "F",
"G": "G",
"H": "H",
"I": "I",
"J": "J",
"K": "K",
"L": "L",
"M": "M",
"N": "N",
"O": "O",
"P": "P",
"Q": "Q",
"R": "R",
"S": "S",
"T": "T",
"U": "U",
"V": "V",
"W": "W",
"X": "X",
"Y": "Y",
"Z": "Z",
"[": "[",
"\": "\\",
"]": "]",
"^": "^",
"_": "_",
"`": "`",
"a": "a",
"b": "b",
"c": "c",
"d": "d",
"e": "e",
"f": "f",
"g": "g",
"h": "h",
"i": "i",
"j": "j",
"k": "k",
"l": "l",
"m": "m",
"n": "n",
"o": "o",
"p": "p",
"q": "q",
"r": "r",
"s": "s",
"t": "t",
"u": "u",
"v": "v",
"w": "w",
"x": "x",
"y": "y",
"z": "z",
"{": "{",
"|": "|",
"}": "}",
"~": "~",
"←": "←",
"↑": "↑",
"→": "→",
"↓": "↓",
"↔": "↔",
"⇐": "⇐",
"⇑": "⇑",
"⇒": "⇒",
"⇓": "⇓",
"⇔": "⇔",
"‘": "‘",
"’": "’",
"“": "“",
"”": "”",
"‚": "‚",
"„": "„",
"–": "-",
"—": "–",
" ": " ",
"¡": "¡",
"§": "§",
"¦": "¦",
"©": "©",
"®": "®",
"™": "™",
"¢": "¢",
"£": "£",
"¥": "¥",
"€": "€",
"±": "±",
"µ": "µ",
"&183;": "·",
"°": "°",
"¹": "¹",
"²": "²",
"³": "³",
"¶": "¶",
"·": "·",
"¼": "¼",
"½": "½",
"¾": "¾",
"¿": "¿",
"†": "†",
"‡": "‡",
"•": "•",
"…": "…",
}train_X = df_train["message"]
test_X = df_test["message"]
train_y = df_train["label"]
test_y = df_test["label"]train_X0 ahhhh...just woken up!had a bad dream about u ...
1 you can never do nothing
2 now u sound like manky scouse boy steve,like! ...
3 mum say we wan to go then go... then she can s...
4 never y lei... i v lazy... got wat? dat day ü ...
...
4174 just woke up. yeesh its late. but i didn't fal...
4175 what do u reckon as need 2 arrange transport i...
4176 free entry into our £250 weekly competition ju...
4177 -pls stop bootydelious (32/f) is inviting you ...
4178 tell my bad character which u dnt lik in me. ...
Name: message, Length: 4179, dtype: objectimport re
import string
def custom_standardizer(x):
for i in entity_map:
x = tf.strings.regex_replace(x, re.escape(i), entity_map.get(i, ""))
x = tf.strings.lower(x)
x = tf.strings.regex_replace(x, f"[{re.escape(string.punctuation)}]", "")
return x
vectorization = keras.layers.TextVectorization(
# standardize=custom_standardizer,
max_tokens=20_000,
output_mode="int",
output_sequence_length=500,
)
vectorization.adapt(np.array(train_X))model = tf.keras.Sequential(
[
vectorization,
keras.layers.Embedding(20_000 + 1, 128, input_length=500),
keras.layers.Dropout(0.5),
keras.layers.Conv1D(128, 7, padding="valid", activation="relu", strides=3),
keras.layers.Conv1D(128, 7, padding="valid", activation="relu", strides=3),
keras.layers.GlobalMaxPooling1D(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation="sigmoid", name="predictions"),
]
)
model.compile(
loss="binary_crossentropy",
optimizer="adam",
metrics=["accuracy"],
)
model.summary()d:\My_Projects\blog\blog\interactive\.venv\lib\site-packages\keras\src\layers\core\embedding.py:90: UserWarning: Argument `input_length` is deprecated. Just remove it.
warnings.warn(Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ text_vectorization_1 │ ? │ 0 (unbuilt) │ │ (TextVectorization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ embedding_2 (Embedding) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_4 (Dropout) │ ? │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv1d_4 (Conv1D) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv1d_5 (Conv1D) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_max_pooling1d_2 │ ? │ 0 │ │ (GlobalMaxPooling1D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_5 (Dropout) │ ? │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ predictions (Dense) │ ? │ 0 (unbuilt) │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 0 (0.00 B)
Trainable params: 0 (0.00 B)
Non-trainable params: 0 (0.00 B)
history = model.fit(
train_X,
train_y,
validation_data=(test_X, test_y),
batch_size=32,
epochs=3,
verbose=1,
)Epoch 1/3
131/131 ━━━━━━━━━━━━━━━━━━━━ 8s 43ms/step - accuracy: 0.8469 - loss: 0.4181 - val_accuracy: 0.9820 - val_loss: 0.0693
Epoch 2/3
131/131 ━━━━━━━━━━━━━━━━━━━━ 5s 40ms/step - accuracy: 0.9828 - loss: 0.0651 - val_accuracy: 0.9856 - val_loss: 0.0606
Epoch 3/3
131/131 ━━━━━━━━━━━━━━━━━━━━ 5s 39ms/step - accuracy: 0.9955 - loss: 0.0202 - val_accuracy: 0.9820 - val_loss: 0.0609def plot_loss(history):
plt.plot(history.history["loss"], label="tra_loss")
plt.plot(history.history["val_loss"], label="val_loss")
plt.ylim([0, 0.5])
plt.xlabel("Epoch")
plt.ylabel("Error")
plt.legend()
plt.grid(True)
plot_loss(history)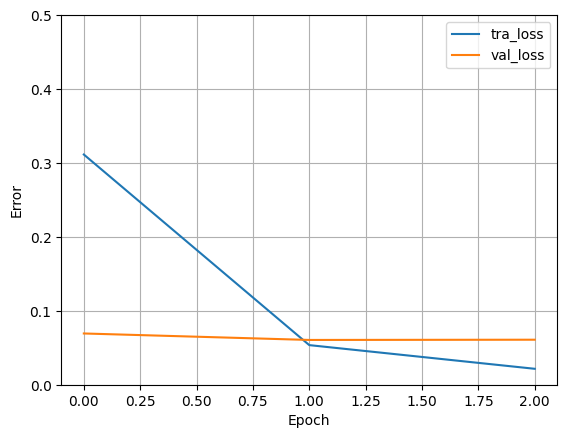
# function to predict messages based on model
# (should return list containing prediction and label, ex. [0.008318834938108921, 'ham'])
def predict_message(pred_text):
if type(pred_text) is str:
pred_text = np.array([pred_text]).astype(object)
if type(pred_text) is list:
pred_text = np.array(pred_text).astype(object)
prediction = model.predict(pred_text)
score = prediction[0][0]
if score > 0.5:
return [score, "spam"]
else:
return [score, "ham"]
# pred_text = "how are you doing today?"
pred_text = [
"how are you doing today",
"sale today! to stop texts call 98912460324",
"i dont want to go. can we try it a different day? available sat",
"our new mobile video service is live. just install on your phone to start watching.",
"you have won £1000 cash! call to claim your prize.",
"i'll bring it tomorrow. don't forget the milk.",
"wow, is your arm alright. that happened to me one time too",
]
prediction = predict_message(pred_text)
print(prediction)1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 183ms/step
[np.float32(0.0054872185), 'ham']# Run this cell to test your function and model. Do not modify contents.
def test_predictions():
test_messages = [
"how are you doing today",
"sale today! to stop texts call 98912460324",
"i dont want to go. can we try it a different day? available sat",
"our new mobile video service is live. just install on your phone to start watching.",
"you have won £1000 cash! call to claim your prize.",
"i'll bring it tomorrow. don't forget the milk.",
"wow, is your arm alright. that happened to me one time too",
]
test_answers = ["ham", "spam", "ham", "spam", "spam", "ham", "ham"]
passed = True
for msg, ans in zip(test_messages, test_answers):
prediction = predict_message(msg)
if prediction[1] != ans:
passed = False
if passed:
print("You passed the challenge. Great job!")
else:
print("You haven't passed yet. Keep trying.")
test_predictions()1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 197ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 27ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 50ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 24ms/step
You passed the challenge. Great job!